Ollama is one of the easiest ways for running large language models (LLMs) locally on your own machine.
It’s like Docker. You download publicly available models from Hugging Face using its command line interface. Connect Ollama with a graphical interface and you have a chatGPT alternative local AI tool.
In this guide, I’ll walk you through some essential Ollama commands, explaining what they do and share some tricks at the end to enhance your experience.
Table of Contents
Checking available commands
Before we dive into specific commands, let’s start with the basics. To see all available Ollama commands, run:
ollama --helpThis will list all the possible commands along with a brief description of what they do. If you want details about a specific command, you can use:
ollama <command> --helpFor example, ollama run --help will show all available options for running models.
Here’s a glimpse of essential Ollama commands, which we’ve covered in more detail further in the article.
| Command | Description |
|---|---|
ollama create |
Creates a custom model from a Modelfile, allowing you to fine-tune or modify existing models. |
ollama run <model> |
Runs a specified model to process input text, generate responses, or perform various AI tasks. |
ollama pull <model> |
Downloads a model from Ollama’s library to use it locally. |
ollama list |
Displays all installed models on your system. |
ollama rm <model> |
Removes a specific model from your system to free up space. |
ollama serve |
Runs an Ollama model as a local API endpoint, useful for integrating with other applications. |
ollama ps |
Shows currently running Ollama processes, useful for debugging and monitoring active sessions. |
ollama stop <model> |
Stops a running Ollama process using its process ID or name. |
ollama show <model> |
Displays metadata and details about a specific model, including its parameters. |
ollama run <model> "with input" |
Executes a model with specific text input, such as generating content or extracting information. |
ollama run <model> < "with file input" |
Processes a file (text, code, or image) using an AI model to extract insights or perform analysis. |
1. Downloading an LLM
If you want to manually download a model from the Ollama library without running it immediately, use:
ollama pull <model_name>
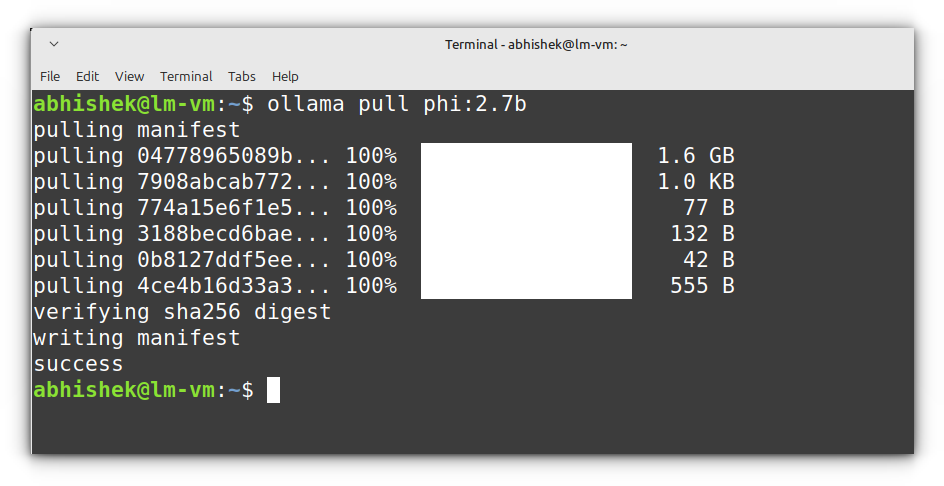
For instance, to download Llama 3.2 (300M parameters):
ollama pull phi:2.7b
This will store the model locally, making it available for offline use.
📋
2. Running an LLM
To begin chatting with a model, use:
ollama run <model_name>For example, to run a small model like Phi2:
ollama run phi:2.7b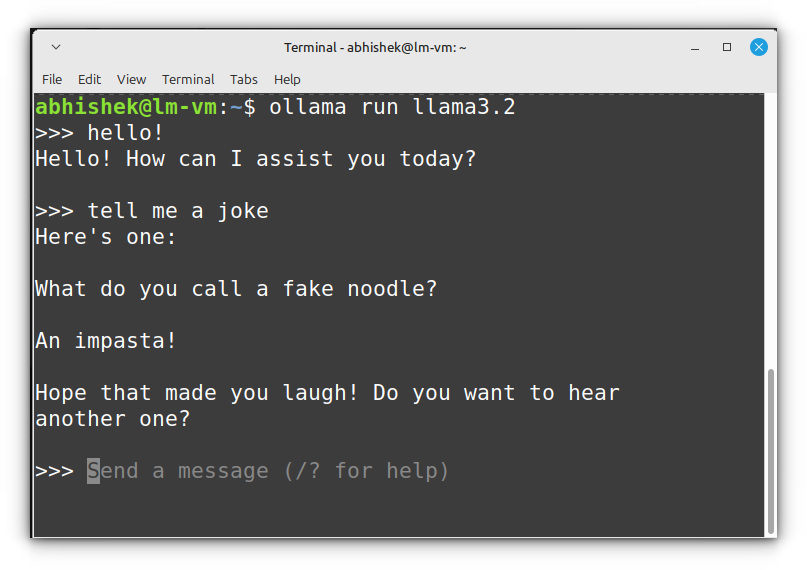
If you don’t have the model downloaded, Ollama will fetch it automatically. Once it’s running, you can start chatting with it directly in the terminal.
Some useful tricks while interacting with a running model:
- Type
/set parameter num_ctx 8192to adjust the context window. - Use
/show infoto display model details. - Exit by typing
/bye.
3. Listing installed LLMs
If you’ve downloaded multiple models, you might want to see which ones are available locally. You can do this with:
ollama listThis will output something like:
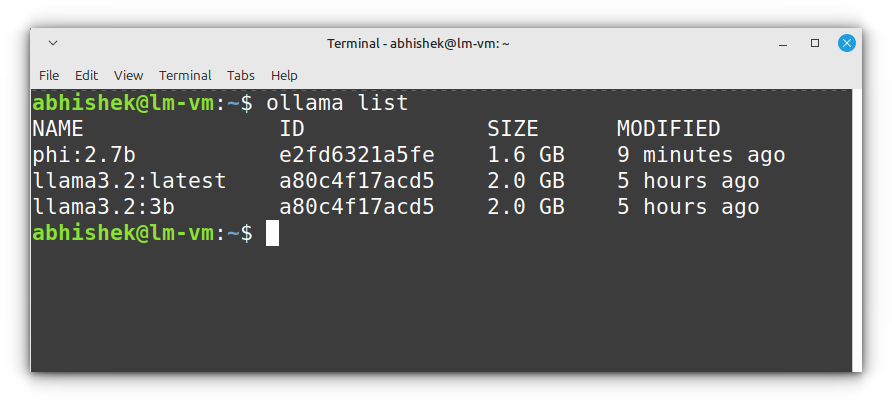
This command is great for checking which models are installed before running them.
4. Checking running LLMs
If you’re running multiple models and want to see which ones are active, use:
ollama psYou’ll see an output like:
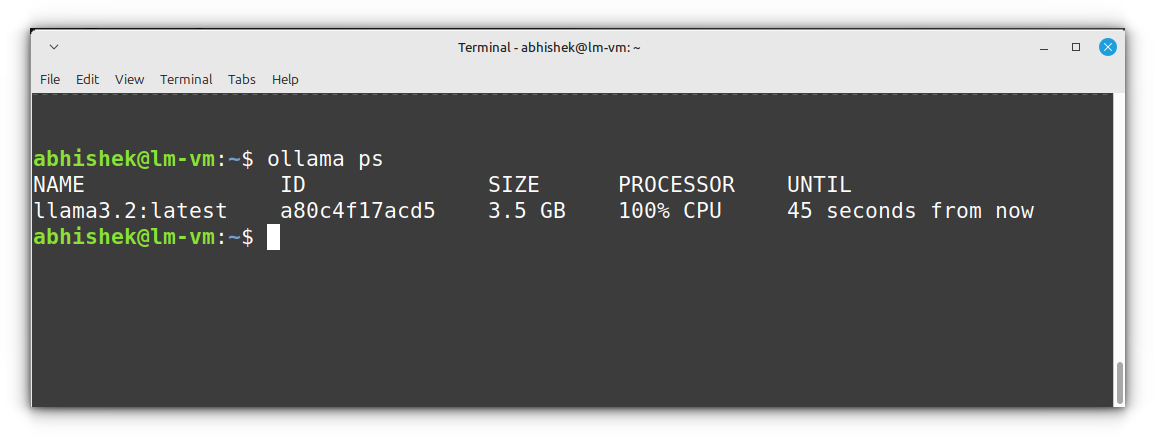
To stop a running model, you can simply exit its session or restart the Ollama server.
5. Starting the ollama server
The ollama serve command starts a local server to manage and run LLMs.
This is necessary if you want to interact with models through an API instead of just using the command line.
ollama serve
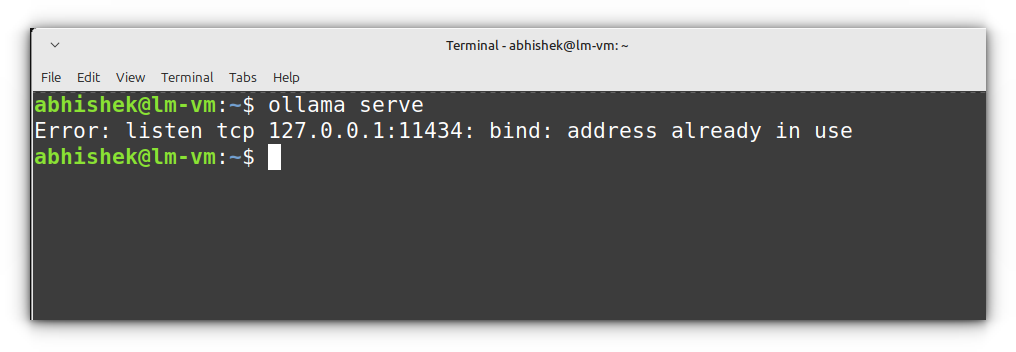
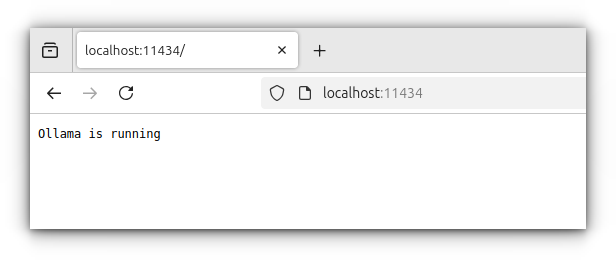
By default, the server runs on http://localhost:11434/, and if you visit this address in your browser, you’ll see “Ollama is running.”
You can configure the server with environment variables, such as:
OLLAMA_DEBUG=1→ Enables debug mode for troubleshooting.OLLAMA_HOST=0.0.0.0:11434→ Binds the server to a different address/port.
6. Updating existing LLMs
There is no ollama command for updating existing LLMs. You can run the pull command periodically to update an installed model:
ollama pull <model_name>If you want to update all the models, you can combine the commands in this way:
ollama list | tail -n +2 | awk '{print $1}' | xargs -I {} ollama pull {}That’s the magic of AWK scripting tool and the power of xargs command.
Here’s how the command works (if you don’t want to ask your local AI).
Ollama lists all the models and you take the ouput starting at line 2 as line 1 doesn’t have model names. And then AWK command gives the first column that has the model name. Now this is passed to xargs command that puts the model name in {} placeholder and thus ollama pull {} runs as ollama pull model_name for each installed model.
7. Custom model configuration
One of the coolest features of Ollama is the ability to create custom model configurations.
For example, let’s say you want to tweak smollm2 to have a longer context window.
First, create a file named Modelfile in your working directory with the following content:
FROM llama3.2:3b
PARAMETER temperature 0.5
PARAMETER top_p 0.9
SYSTEM You are a senior web developer specializing in JavaScript, front-end frameworks (React, Vue), and back-end technologies (Node.js, Express). Provide well-structured, optimized code with clear explanations and best practices.
Now, use Ollama to create a new model from the Modelfile:
ollama create js-web-dev -f Modelfile
Once the model is created, you can run it interactively:
ollama run js-web-dev "Write a well-optimized JavaScript function to fetch data from an API and handle errors properly."
If you want to tweak the model further:
- Adjust
temperaturefor more randomness (0.7) or strict accuracy (0.3). - Modify
top_pto control diversity (0.8for stricter responses). - Add more specific system instructions, like
"Focus on React performance optimization."
Some other tricks to enhance your experience
Ollama isn’t just a tool for running language models locally, it can be a powerful AI assistant inside a terminal for a variety of tasks.
Like, I personally use Ollama to extract info from a document, analyze images and even help with coding without leaving the terminal.
💡
Running Ollama for image processing, document analysis, or code generation without a GPU can be excruciatingly slow.
Summarizing documents
Ollama can quickly extract key points from long documents, research papers, and reports, saving you from hours of manual reading.
That said, I personally don’t use it much for PDFs. The results can be janky, especially if the document has complex formatting or scanned text.
If you’re dealing with structured text files, though, it works fairly well.
ollama run phi "Summarize this document in 100 words." < french_revolution.txt
Image analysis
Though Ollama primarily works with text, some vision models (like llava or even deepseek-r1) are beginning to support multimodal processing, meaning they can analyze and describe images.
This is particularly useful in fields like computer vision, accessibility, and content moderation.
ollama run llava:7b "Describe the content of this image." < cat.jpg
Code generation and assistance
Debugging a complex codebase? Need to understand a piece of unfamiliar code?
Instead of spending hours deciphering it, let Ollama have a look at it. 😉
ollama run phi "Explain this algorithm step-by-step." < algorithm.py
Additional resources
If you want to dive deeper into Ollama or are looking to integrate it into your own projects, I highly recommend checking out freeCodeCamp’s YouTube video on the topic.
It provides a clear, hands-on introduction to working with Ollama and its API.
Conclusion
Ollama makes it possible to harness AI on your own hardware. While it may seem overwhelming at first, once you get the hang of the basic commands and parameters, it becomes an incredibly useful addition to any developer’s toolkit.
That said, I might not have covered every single command or trick in this guide, I’m still learning myself!
If you have any tips, lesser-known commands, or cool use cases up your sleeve, feel free to share them in the comments.
I feel that this should be enough to get you started with Ollama, it’s not rocket science. My advice? Just fiddle around with it.
Try different commands, tweak the parameters, and experiment with its capabilities. That’s how I learned, and honestly, that’s the best way to get comfortable with any new tool.
Happy experimenting! 🤖